
一致性哈希
一致性哈希 Consistent Hash
概述
一致性哈希是由传统的哈希算法改进而来的一种算法. 为了解决传统哈希算法对于哈希表长度发生变化导致大量数据对象需要重哈希的问题.
前言
当我们去车站买票的时候, 经常看到这样一个现象. 车站只开了一个窗口, 窗口前排着长长的队伍.突然, 旁边的售票窗口打开了, 然后后面排队的人们轰的一下就会跑到另外一个窗口去. 或者是有某个窗口突然被关闭, 人们就得排到还打开的窗口去.
然后再来回顾一下传统的哈希表, 计算方法我们就采用简单又常见的取余法
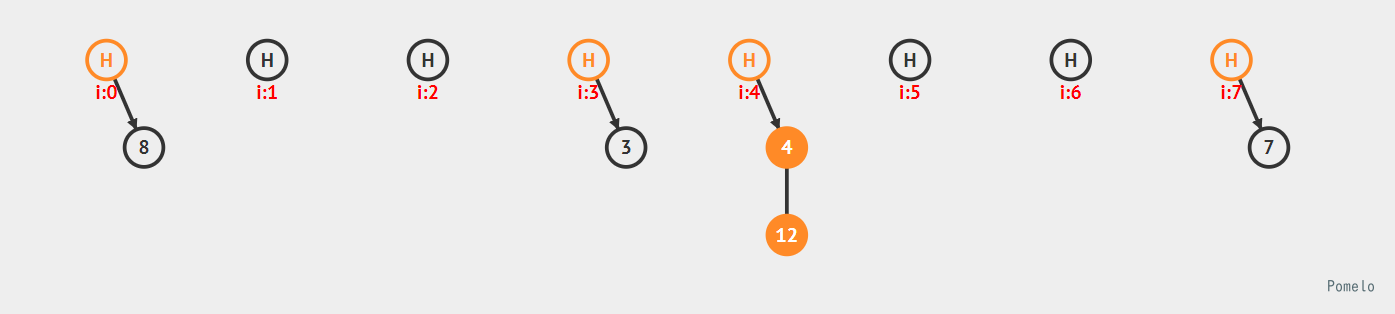
我们将 {3, 4, 7, 8, 12} 五个数字对这个哈希表长n = 8取余, 能得到上面图片中的哈希表.
我们将哈希表长减到n = 5, 依旧是存储上面的5个数字, 此时哈希表就变成了下面这样
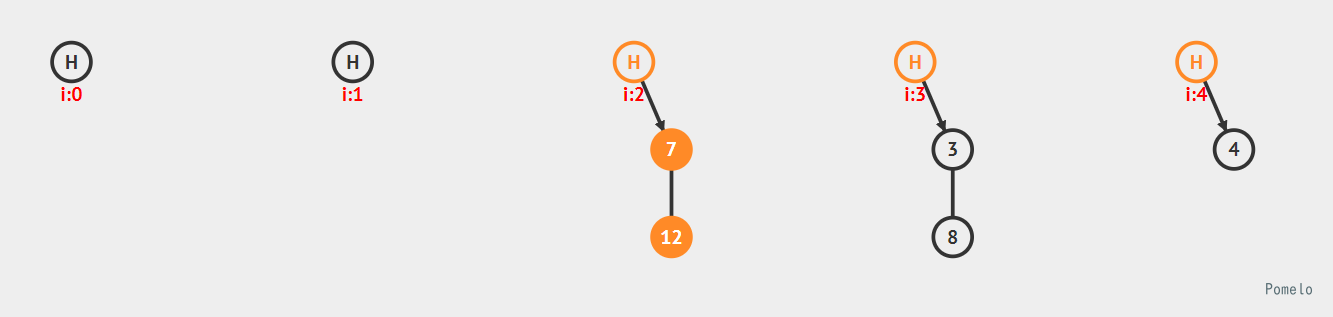
基本上所有的元素都改变了在表中的位置, 也就是说如果哈希表的长度发生改变, 大部分元素都要重哈希来定位自己在新表中的位置.
- 做个变化的比较
1 | if __name__ == '__main__': |
也就是说, 对于表中的一个节点会有大量的数据会被重新哈希定位新的位置
在大部分程序语言中, 哈希表会指定一个默认长度 (Python的dict默认长度为8), 但并不推荐使用使用这个默认值, 因为这个值并不能满足大部分的使用需求, 如果使用了这个默认值通常需要进行调整长度.
如果哈希表长度经常发生变化的话, 数据要经常重新定位. 这工作量十分巨大.
为什么动一个节点就要殃及池鱼呢? 有没有什么很好的办法能够使得每次的调整造成的影响减小或者说只影响于调整的位置?
- 申请长度足够的哈希表, 这样少量的增减不会对整体的数据产生影响
- 就像我们在车站开放100万个窗口, 增减几个窗口对大部分用户不会有什么影响, 毕竟哪个车站会有这么多人呢
- 如果只是短时调整, 可以让数据在原地等待节点恢复原状
- 车站的售票员临时去上了个厕所, 就让用户在原地等待一会
第一个方案似乎会更好一些, 可是申请大量的空间不使用也是很浪费的, 所以在此基础上再次进行优化, 于是就有了一致性哈希算法.
性质
平衡性(Balance)
单调性(Monotonicity)
分散性(Spread)
负载(Load)
平滑性(Smoothness)
算法原理
- 这里应用简单的哈希计算方法 (取余法)
我们还是要去买票
这次车站想了一个新的办法来管理车站的售票窗口, 去买票的人需要先去取个号码.
车站打开了A, B, C 三个售票窗口, 并且规定领到号码的人要按照号码顺序在圆形大厅中顺时针去排队买票
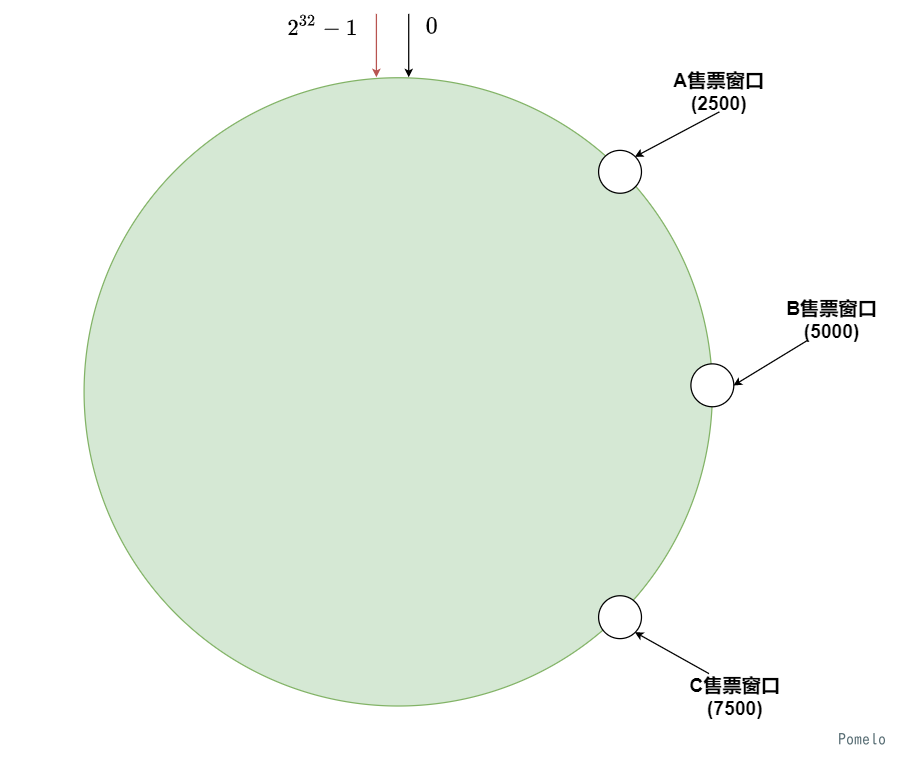
此时车站来了一万个人, 并且领取了号码准备买票
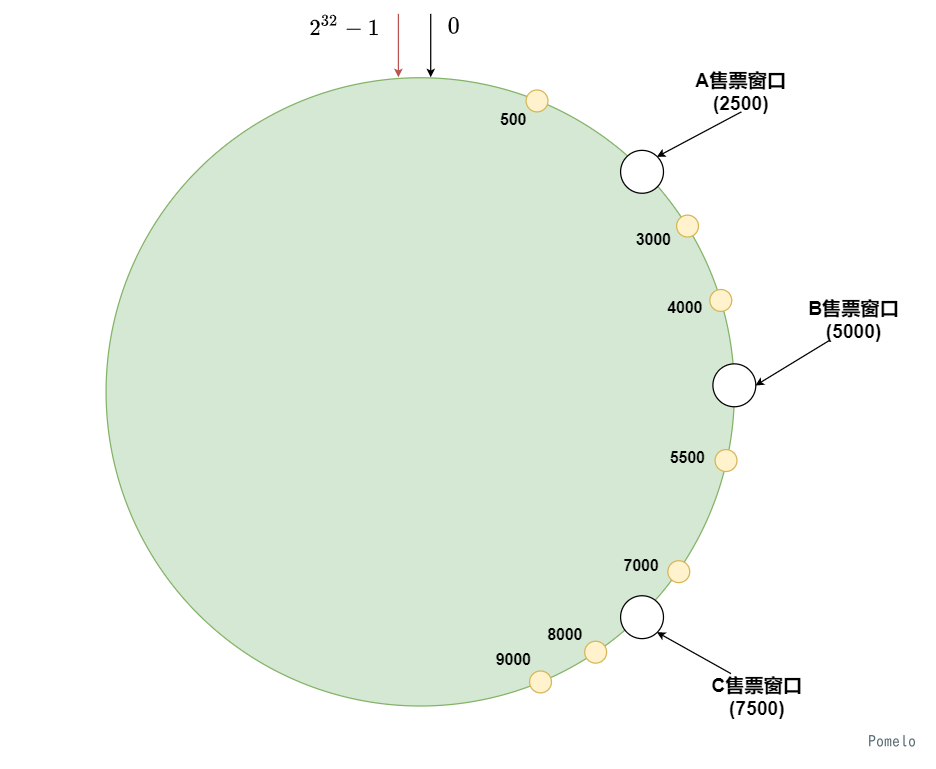
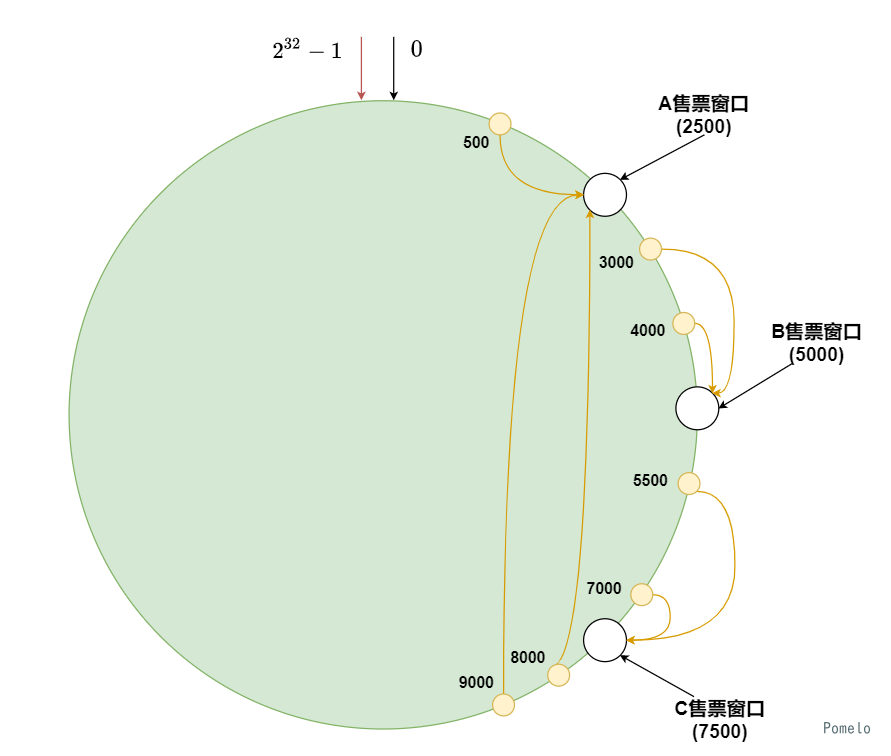
根据车站的管理规则, 他们应该去到对应的窗口买票, 500号选手顺序应当到A售票窗口买票
扩展和移除
新增
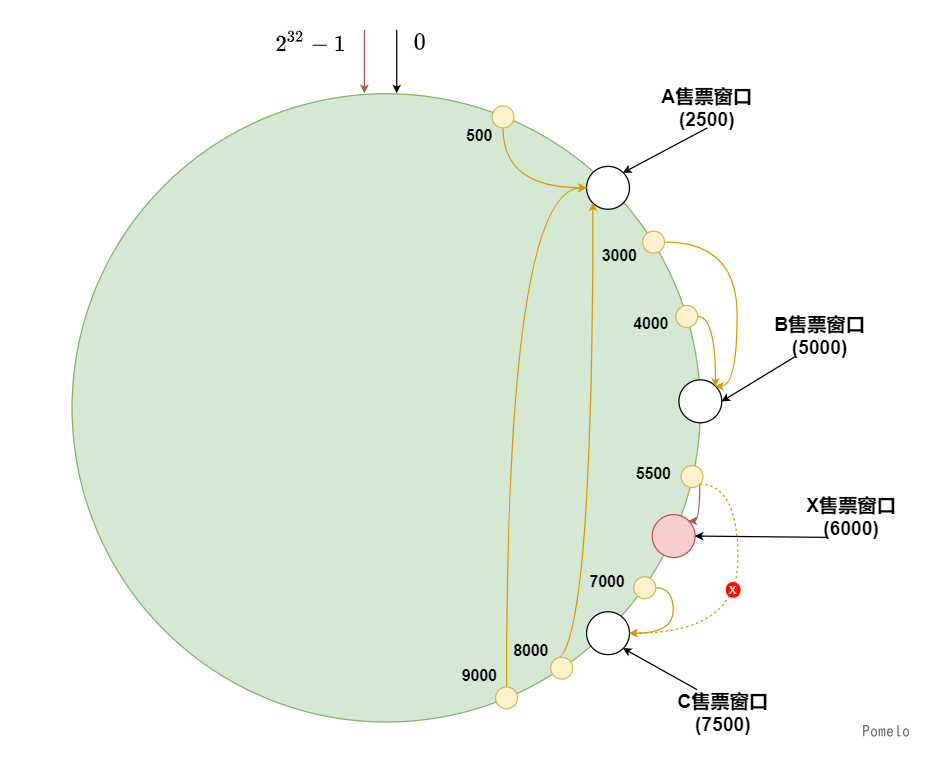
不少的人觉得, 排队买票的时间太久了, 强烈要求车站增开售票窗口.
如下图, 要在B窗口和C窗口之间新增一个X窗口, 此时5500的用户就不需要去到C窗口买票了, 直接去到X窗口买票
此时受到影响的也只是B窗口和X窗口之间的用户, 位于X窗口和B窗口之间的请求会从C窗口上转移至X窗口上.
其他用户还是去对应的窗口买票, 这样对整体的影响将大大减小.
移除
当移除掉一个售票窗口, 受到影响的用户又有多少呢?
同理可得. 如下图, 我们想要移除B窗口的话, 此时A窗口和B窗口之间的请求将顺着哈希环全部转移至C窗口, 其他位置的用户并不会收到影响.
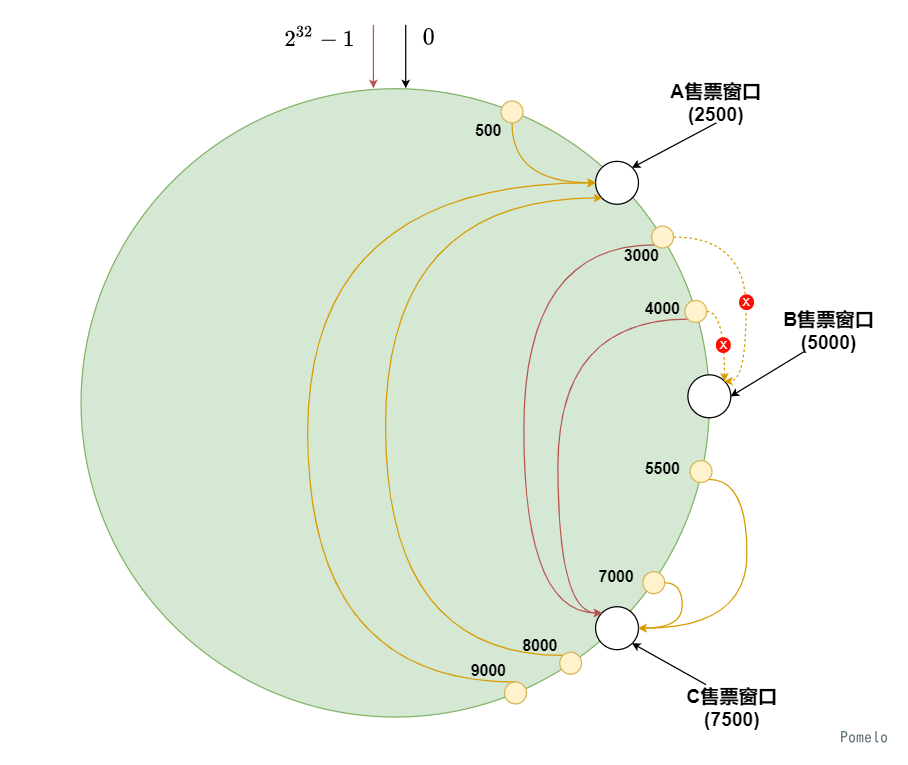
由上可见, 如果有N个售票窗口, 并且这N个窗口均匀分布, 那么新增或移除K个窗口只会对 $\frac KN$ 的用户造成影响. 这远远小于传统哈希算法改变表长带来的影响
分配倾斜
城市下个星期要开展一个盛大的活动, 来往的人也变得多了起来, 人们照常去售票大厅购票, 于是排队的场面就变成了这样
A窗口的售票员操劳过度, 大量的人排在了A窗口前.
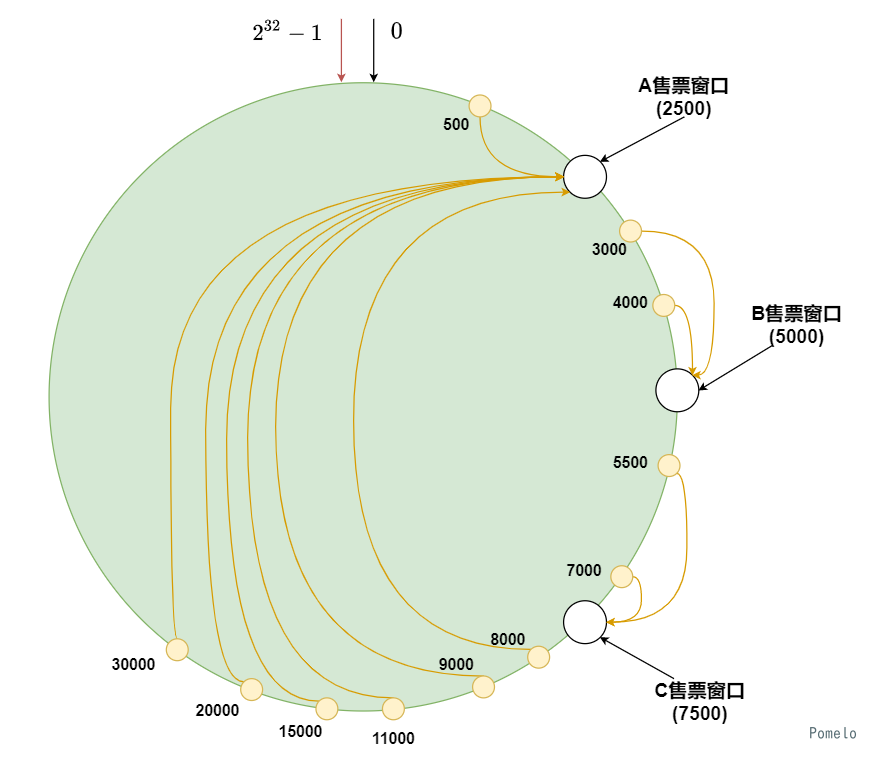
这是由于窗口的数量对于日常的人流分配是均匀的, 但是人数突然激增或者减少, 这个平衡就会被打破.
对于这个情况, 在不改变窗口数量的情况下, 有没有办法让人数在分配时更加的均匀呢?
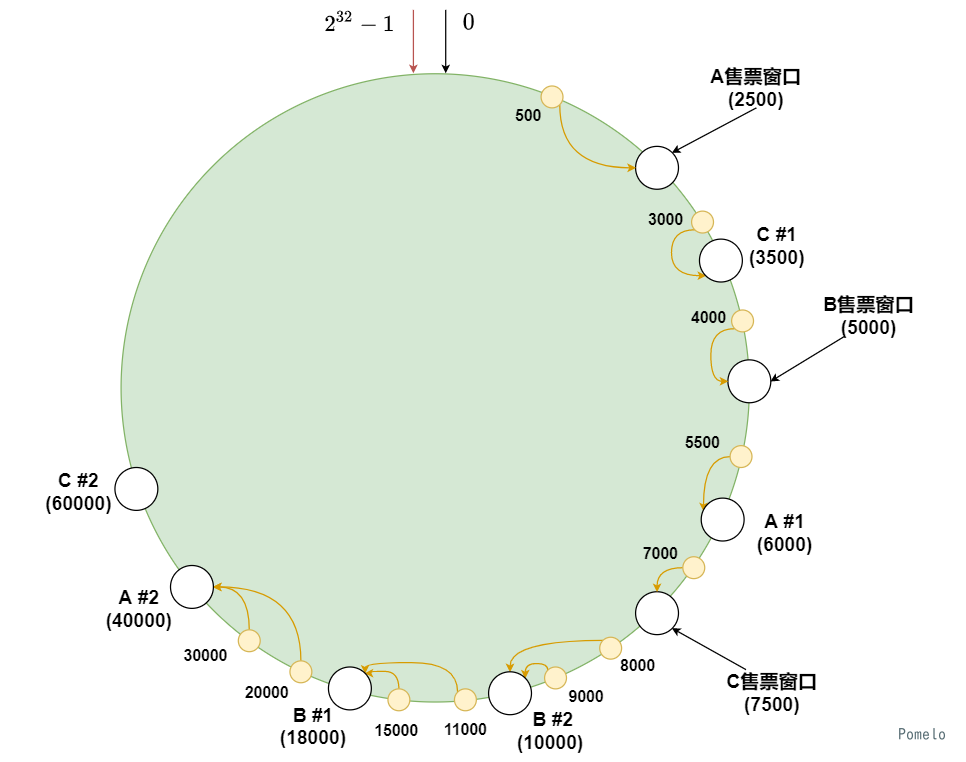
我们需要把同一个时段的人能够更均匀的分配到每一个窗口, 就需要再将窗口分配得更密集一点, 可是窗口只有那么多个怎么办呢?
我们可以建造一些购票机器使人流更分散均匀.
我们使用虚拟节点 (购票机器) 来完成这个优化, 将真实的售票窗口虚拟出很多的窗口并更均匀的分配到大厅中, 实际上在虚拟节点购票的用户实际上是在真实的窗口出票的.
实践
微软提交社区的一致性哈希算法, 具体数据结构使用了排序的Map, 查找效率较无序Map大大提升.
- 忽略锁的部分
1 | /** |
应用
一致性哈希被应用于分布式系统中, 在分布式数据库和分布式缓存中被广泛使用.
- Data partitioning in Azure Cosmos DB
- 服务器负载均衡
- MemCache分布式内存对象缓存系统
比较
传统哈希表因为表长改变需要对极大部分数据进行重哈希, 产生大量的工作量.
而一致性哈希使数据几乎不会产生冲突的分布在整数环上, 然后再对整数环切分处理, 在可用节点发生改变的时候, 只会对改变节点至上一个节点中的对象造成影响
对于N个节点 (或槽), K个关键字的渐近时间复杂度
| 传统哈希表 | 一致性哈希 | |
|---|---|---|
| 增加一个节点 | $O(K)$ | $O(\frac KN + \log N)$ |
| 移除一个节点 | $O(K)$ | $O(\frac KN + \log N)$ |
| 增加一个关键字 | $O(1)$ | $O(\log N)$ |
| 移除一个关键字 | $O(1)$ | $O(\log N)$ |
问题
- 哈希环本质的数据结构
- 环的大小范围?
- 一定是顺时针查找?
- 取余结果相同的怎么放
参考资料
- [我们是如何高效实现一致性哈希的][https://github.com/xitu/gold-miner/blob/master/TODO1/how-to-implement-consistent-hashing-efficiently.md]
- [zhihu – 面试必备: 什么是一致性哈希算法][https://zhuanlan.zhihu.com/p/34985026]
- [zhihu – 一致性哈希算法原理MOOC][https://zhuanlan.zhihu.com/p/78285304]
- [zhihu – 5分钟理解一致性哈希算法][https://zhuanlan.zhihu.com/p/40944685]
- [zhihu – 一致性哈希算法,在分布式开发中你必须会写,来看完整代码][https://zhuanlan.zhihu.com/p/95683526]
- [CSDN – 一致性哈希的数据结构][https://www.cnblogs.com/xrq730/p/5186728.html]
 微信
微信 支付宝
支付宝
